
Cloud Architecture - Live in the Cloud Part 2!
Live in the Cloud Part 2
Now let’s check some cloud architecture structures using the Kubernetes platform as an example.
Here in this image, you can see that I have a namespace that belongs to a cloud cluster in a data centre that contains two pods deployed there.
Overview
The first Pod is with two containers as you can see a Pod can have more containers in good explain for having that is some application may have a side container with an admin console.
The other pod is configured with a Statefulset which means it’s stateful and has one container typical software that uses this configuration is a database.
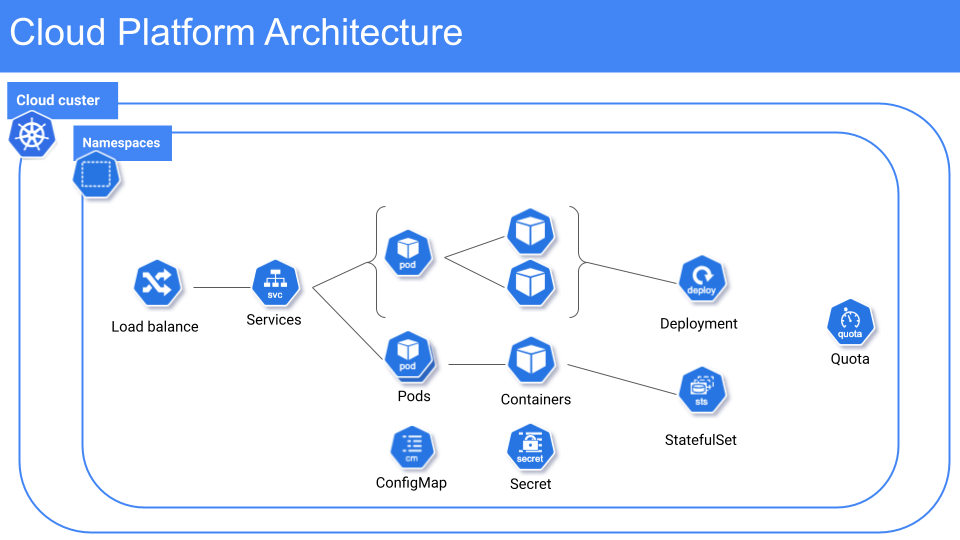
I will dissect all those Kubernetes objects to explain in the next section.
Those are Kubernetes objects that you can use CLI commands tools to apply or user interfaces to help administrate those elements like Openshift Container Platform.
1 Cloud Cluster
A cloud cluster like a Kubernetes cluster or Openshift Cluster is a group of nodes that run containerised applications. Every node is a machine which will be part of a data centre. Normally companies use a dev and test cloud cluster built in one data centre and a pre and prod cluster in another to avoid any interferences between them. Also as good practice, it’s advised to have a second data centre for your production environment for a contingency plan.
A cluster normally consists of a main node and worker nodes, in addition, you can also have infra nodes to handle specific non-applications workloads such as DNS services, monitoring, logging, storage and more.
You can find below an example of a Kubernetes YAML configuration file for creating a cluster in any cloud provider
apiVersion: v1
kind: Service
metadata:
name: my-cloud-cluster
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: my-app
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-deployment
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app-container
image: my-image: latest
ports:
- containerPort: 80802 Namespace
It’s a tool/structure that provides an insolate environment dividing your cluster into individual projects for better resource usage organisation and management. It’s a handy way to group and control resources in a multi-tenant domain.
Here is a command line to create your namespace
kubectl create namespace <namespace-name>Normally companies will create a dev and test/UAT namespace per team/project in their dev cluster and Pre and Prod namespace in the production cluster.
3 Pod
It’s a single instance of a running process in a cluster. It can contain one or more containers with the configuration and specifications for running them. It’s generally immutable which means that once it’s created it cannot change its specifications. To change some aspects of the pod you need to redeploy it however you can update its configmaps and secrets by doing changes that will reflect without recreating it.
A simple example of doing a source 2 image Pod creation using the Openshift Container Platform command line tool:
oc new-app https://github.com/example/my-appIn Kubernetes you will need a yml file to configure it then you can apply it via the command line
4 Container
It’s a lightweight, portable box that contains everything needed to run a piece of software. It includes application code, runtime, system tools, libraries, dependencies, settings, etc.
Here an example:
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 805 Statefulset
As the name already says it is normally used for stateful applications like a database, which can guarantee the ordering and uniqueness of those types of pods.
Example using MySQL
---
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- port: 3306
name: mysql
cluster: None
selector:
app: mysql
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: "mysql"
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
ports:
- containerPort: 3306
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: my-secret-pw
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: mysql-persistent-storage
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi6 Deployment
It’s a Kubernetes object that manages ReplicaSets and provides declarative updates to applications. Some of the features are rolling updates and rollbacks.
Example:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 807 Services
Enable networking and load balancing for pods. You need to create your service that exposes the port and the network protocol for communication with that you can create a route to direct the traffic and make it available outside of the cluster
Example:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
labels:
app: nginx
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIP8 Load Balance
It exposes the service externally using a cloud provider load balance such as HAProxy or Ingress. An Ingress is an API object that manages external access to services within a cluster typically over HTTP.
9 ConfigMap and Secrets
Creates a Kubernetes object that allows configuration data such as data source to be stored in the particular namespace.
ConfigMaps can be used to configure applications without embedding those configurations in the application container image.
A good example of this is when you need to change an application’s properties. If these properties are hardcoded in your files, you will need to redeploy the application. However, by using a ConfigMap to store property variables, you can update the application’s configuration without redeploying it.
ConfigMap for MySQL example:
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
data:
database.url: "jdbc:mysql://mysql-service:3306/mydatabase"Secret is very similar to ConfigMap but it’s designed to store sensitive data such as passwords, tokens, SSH keys, and certs, in an encrypted way.
A secret example with the user and password for that database connection is shown in the previous code box above.
apiVersion: v1
kind: Secret
metadata:
name: mysql-secret
type: Opaque
data:
username: bXlzcWx1c2Vy # base64 encoded value of 'mysqluser'
password: bXlzcWxwYXNzd29yZA== # base64 encoded value of 'mysqlpassword'10 Quota
It’s a method to limit resource usage for a namespace. Typically if you need more CPU, memory and storage you probably need to contact your cluster admin to approve and configure this for you.
Quota yaml file example:
apiVersion: v1
kind: ResourceQuota
metadata:
name: example-quota
namespace: my-namespace
spec:
hard:
pods: "10"
requests.cpu: "4"
requests.memory: "8Gi"
limits.cpu: "8"
limits.memory: "16Gi"
configmaps: "5"
persistentvolumeclaims: "5"
services: "10"
secrets: "10"
replicationcontrollers: "10"
resourcequotas: "1"11 Vertical Pod Autoscaler (VPA)
The Vertical Pod Autoscaler (VPA) is a Kubernetes component that automatically adjusts the resource limits and requests (CPU and memory) for containers in pods. Unlike the Horizontal Pod Autoscaler (HPA), which scales the number of pod replicas based on resource usage
You need to install the VPA components in your cluster.
kubectl apply -f https://github.com/kubernetes/autoscaler/releases/download/vpa-release-0.9.2/vpa-v0.9.2.yamlHere’s an example VPA YAML configuration for the nginx-deployment.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: nginx-vpa
namespace: default
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
updatePolicy:
updateMode: Auto12 Horizontal Pod Autoscaler (HPA)
Automatically scales the number of pods in a deployment, replica set, or stateful set based on observed CPU utilization or other custom metrics.
Ensure that the metrics server is deployed in your Kubernetes cluster. You can install it in your cluster by doing the following command:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yamlHere an yaml file example
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 5013 Custom Resource Definitions (CRDs)
Extend Kubernetes capabilities by allowing users to define their resource types. CRDs enable the creation of new API objects beyond the built-in Kubernetes objects.
You can find the ActiveMQ CRD example in Broker ActiveMQ Artemis Address CRD Yaml example
Conclusion
Concluding part 2
In conclusion, grasping the nuances of cloud architecture, especially in the Kubernetes realm, unlocks the potential for efficient resource handling and scalable app deployment. 🌐 By dissecting pivotal Kubernetes objects like Pods, Services, and Deployments, we gain insight into crafting resilient, scalable, and manageable cloud-native apps. 💡 With practical examples and clear explanations, navigating cloud infrastructure complexities becomes more accessible, empowering developers and admins to harness cloud tech to its fullest. #CloudArchitecture #Kubernetes #CloudNative #DevOps 🚀
This page was last update at 2026-04-06 23:56